A Technical Odyssey from Relational Database to Graph Database
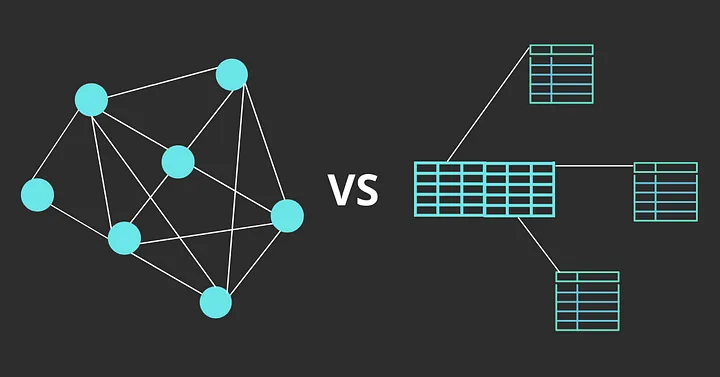
Problem Statement
Imagine a scenario where we need to establish relationships between users, connecting them based on shared activities that they like and don’t like. The goal is to find related users given a starting point, all while preserving the ability to search for information using the user’s name.
For instance, let’s assume we have three users:
- Alice: likes sleeping, hates cooking.
- John: likes jogging, hates cooking.
- Max: likes jogging, hates playing.
The following schema is a demonstration of the relations between users. In our case, the relations should be established based on particular attributes. ALICE has a direct relation with JOHN because they both hate cooking, and JOHN has a direct relation with MAX because they both like jogging. There is an indirect relation between ALICE and MAX. Finding indirect relations makes the problem even harder to solve.
[ALICE] ----- [JOHN] ----- [MAX]
First, we will consider using MySQL, a relational database, to solve the problem, applying the following approaches:
- Adjacency List
- Adjacency List with a tree
Secondly, we will create nodes and edges in Neo4j, a graph database, to solve the problem.
You can use the following docker-compose file to have both databases locally:
services:
mysql-db:
image: mysql:latest
restart: unless-stopped
environment:
MYSQL_ROOT_PASSWORD: root
MYSQL_USER: testuser
MYSQL_PASSWORD: testpassword
MYSQL_DATABASE: test-db
ports:
- "3306:3306"
volumes:
- ./test-service-stack/mysql/data:/var/lib/mysql/
neo4j:
image: neo4j:5
restart: unless-stopped
ports:
- "7474:7474"
- "7687:7687"
volumes:
- ./test-service-stack/neo4j/:/conf
- ./test-service-stack/neo4j/data:/data
- ./test-service-stack/neo4j/import:/import
- ./test-service-stack/neo4j/logs:/logs
- ./test-service-stack/neo4j/plugins:/plugins
environment:
- NEO4J_dbms_memory_pagecache_size=2G
- NEO4J_dbms.memory.heap.initial_size=2G
- NEO4J_dbms_memory_heap_max__size=2G
- NEO4J_AUTH=neo4j/!Secret1
- NEO4JLABS_PLUGINS=["apoc"]
- NEO4J_dbms_security_procedures_whitelist=gds.*, apoc.*
- NEO4J_dbms_security_procedures_unrestricted=gds.*, apoc.*
Adjacency List
In graph theory and computer science, an Adjacency List is a collection of unordered lists that represent a finite graph. In the context of our database design, this approach involves connecting entities when they are saved. Each node in the graph represents a user, and the edges between nodes signify relationships based on shared attributes.
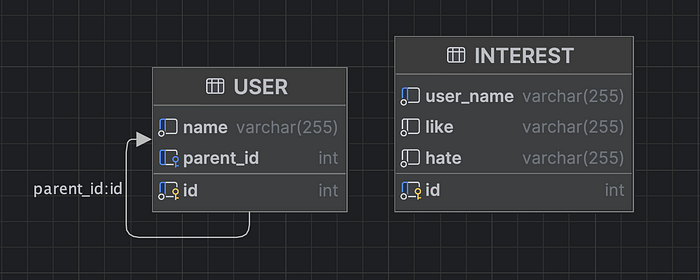
An example of an implementation of an adjacency list in a relational database.
We need two tables: one to store user information and another to store their interests.
CREATE TABLE `USER` (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
parent_id INT
);
ALTER TABLE `USER`
ADD CONSTRAINT FK_user_parent_id
FOREIGN KEY (parent_id) REFERENCES `USER`(id);
ALTER TABLE `USER` ADD INDEX (name);
CREATE TABLE INTEREST (
id INT PRIMARY KEY AUTO_INCREMENT,
user_name VARCHAR(255) NOT NULL,
`like` VARCHAR(255) NOT NULL,
`hate` VARCHAR(255) NOT NULL
);
ALTER TABLE `INTEREST` ADD INDEX (user_name);
The USER table has a foreign key relationship between the ‘id’ and ‘parent_id’ columns. This relationship is necessary for querying related users. INTEREST table stores liked and hated the activities of users.
There is no foreign key between the INTEREST and USER table because we need to insert their interests before inserting users.
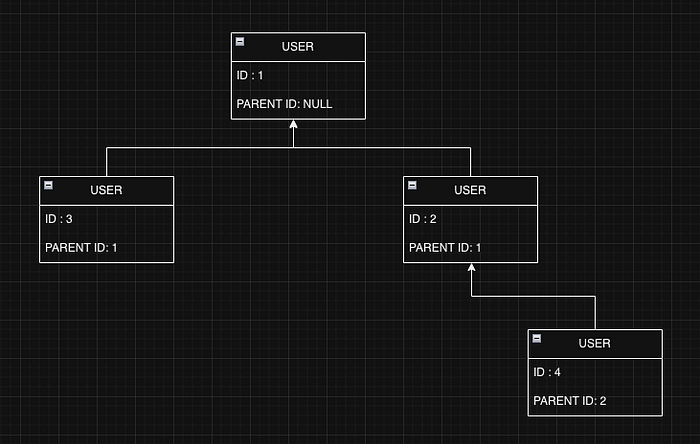
After executing it, we should have the following structure:
Creating Parent-Child Relationships in Database Insertions
We aim to establish a relationship during the user insertion process. As soon as we have a new user with their likes and dislikes defined, we can use the INSERT INTO SELECT query to find other users who share the same interests. This will help us save time while identifying potential matches for the new user.
INSERT INTO `USER`(name, parent_id)
SELECT :name,
u.id
FROM user u
LEFT JOIN INTEREST i1 on u.name = i.user_name
WHERE
i.like = :like
OR i.hate = :hate;
We cannot insert the first user using the given query because the SELECT query within the INSERT INTO statement is not returning any results due to the fact that there are no related users in the database. To solve this, let’s first insert the user along with their interest.
INSERT INTO INTEREST (user_name, `like`, hate) values ('ALICE', 'sleeping', 'cooking');
INSERT INTO USER (name, parent_id) VALUES ('ALICE', NULL);
The other users can be inserted using the INSERT INTO SELECT query after inserting their interests.
For example, assuming we receive the user JOHN, we can run the following queries to insert both its interest and the user:
INSERT INTO INTEREST (user_name, `like`, hate) values ('JOHN', 'jogging', 'cooking');
INSERT INTO `USER`(name, parent_id)
SELECT 'JOHN',
u.id
FROM user u
LEFT JOIN INTEREST i on u.name = i.user_name
WHERE
i.like = 'jogging'
OR i.hate = 'cooking';
After inserting all users, all users will be connected as follows:
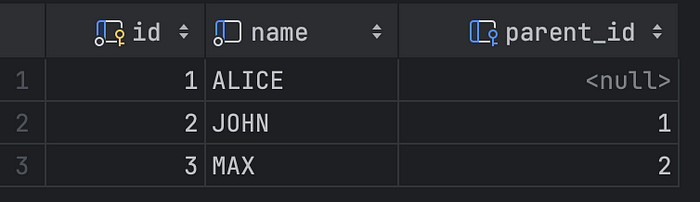
Getting related users using a recursive query
We have succeeded in inserting our users with their parent-child relations. Now, we should be able to retrieve them all by giving the name of a user. Different Relational Database Management Systems (RDMS) offer diverse functions capable of executing various operations. Fortunately, the recursive query is a tool in this arsenal. It’s worth noting that the structure of this query may vary across databases. In our specific scenario, we will leverage the recursive query functionality tailored for MySQL.
WITH RECURSIVE rectree AS (
SELECT *
FROM user
WHERE name = :name
UNION
SELECT u.*
FROM user u
JOIN rectree
ON u.parent_id = rectree.id
UNION
SELECT u.*
FROM user u
JOIN rectree
ON u.id = rectree.parent_id
) SELECT name FROM rectree;
This query, starting from a specified user, recursively retrieves that user’s descendants and ancestors from the user table, forming a hierarchical tree structure. The result is a list of user names.
However, recursive queries could perform slowly if you have a large set of data due to their nature. How can we overcome this problem?
Tree Structure
In the initial method, while we could store new users with a parent ID, establishing connections for all these users was challenging, and required an inefficient approach with a recursive query. If we possess the parent ID during user insertion, we can assign them a distinctive ID. This way, rather than navigating users solely based on the parent ID, we can retrieve them using this unique identifier called tree ID.
Below, you’ll find the same tables as before, but this time, we’ve introduced the tree_id column to the USER table for added context.
CREATE TABLE `USER` (
id INT PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(255) NOT NULL,
parent_id INT,
tree_id INT NOT NULL
);
ALTER TABLE `USER`
ADD CONSTRAINT FK_user_parent_id
FOREIGN KEY (parent_id) REFERENCES `USER`(id);
ALTER TABLE `USER` ADD INDEX (name);
ALTER TABLE `USER` ADD INDEX (tree_id);
CREATE TABLE INTEREST (
id INT PRIMARY KEY AUTO_INCREMENT,
user_name VARCHAR(255) NOT NULL,
`like` VARCHAR(255) NOT NULL,
`hate` VARCHAR(255) NOT NULL
);
ALTER TABLE `INTEREST` ADD INDEX (user_name);
To insert the first user into the database, we will follow the same procedure as before. However, this time, we will assign a unique identifier for the tree_id. All the users who are related to each other will share the same tree ID. But if there are no related users in the database, we will have to assign a new tree ID to the user.
INSERT INTO INTEREST (user_name, `like`, hate) values ('ALICE', 'sleeping', 'cooking');
INSERT INTO USER (name, parent_id, tree_id) VALUES ('ALICE', NULL, 123);
Also, let’s update our INSERT INTO SELECT query so that it can get the tree ID from the related user and insert it for the new one.